この記事について
- 差分更新型ビームサーチライブラリの実装例について説明します。
- 差分更新型のビームサーチについては 高速なビームサーチが欲しい!!! などで既に解説されているため、被る部分については詳しく説明しません。
- この記事に書いたソースコードをプログラミングコンテストで自由に使っていただいて構いませんが、当ブログは損害などに対する責任を負いかねますのでご了承ください。
前提知識
差分更新型のビームサーチとは
木上のビームサーチ、Euler Tour ビームサーチとも呼ばれています1。
ビームサーチは、幅優先探索に枝刈りを取り入れた手法です。探索木における深さ の頂点集合から深さ
の頂点集合を生成し、その中から評価値が高い上位
個を選択します。
のことをビーム幅と呼びます。
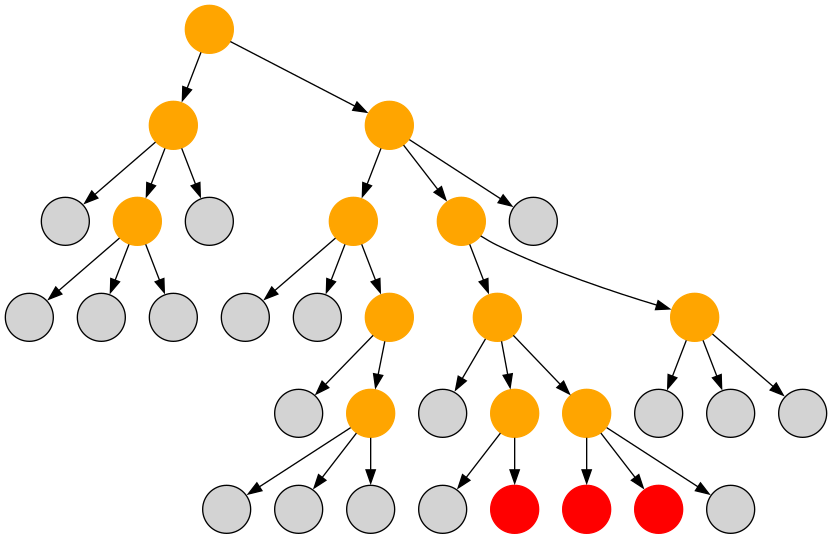
、赤色が探索中のノード、橙色が採用されたノード、灰色が不採用のノード)
愚直なビームサーチでは、頂点ごとに独立した状態を作成します。実装は比較的楽だと思いますが、状態や履歴をコピーする必要が出てくるため、実行速度が遅くなりやすいです2。
そこで、探索木を明示的に作成し、Euler Tour の順序で1つの状態を更新するようにしたものが差分更新型のビームサーチです。探索木の葉を訪れたときに新しい葉の候補を生成します。
状態遷移の履歴は探索木から復元できるため、状態のコピーだけでなく履歴のコピーも省略できます。
深さが の1つの葉を探索するのに最悪で
回の遷移を必要としますが、実際には多くの葉で近い先祖を共有するため、遷移回数は平均して
回よりもかなり少なくなります。
差分更新型ビームサーチは愚直なビームサーチよりも高速に動作する場合が多く3、実装がやや複雑なため、ライブラリを作成しました。
実装
ライブラリ全体を折りたたみに記載しました。コードを読む場合は下の方にある beam_search 関数を最初に読むと分かりやすいかもしれません。
ビームサーチライブラリ
#include <bits/stdc++.h>
#include <atcoder/all>
using namespace std;
namespace beam_search {
// メモリの再利用を行いつつ集合を管理するクラス
template<class T>
class ObjectPool {
public:
// 配列と同じようにアクセスできる
T& operator[](int i) {
return data_[i];
}
// 配列の長さを変更せずにメモリを確保する
void reserve(size_t capacity) {
data_.reserve(capacity);
}
// 要素を追加し、追加されたインデックスを返す
int push(const T& x) {
if (garbage_.empty()) {
data_.push_back(x);
return data_.size() - 1;
} else {
int i = garbage_.top();
garbage_.pop();
data_[i] = x;
return i;
}
}
// 要素を(見かけ上)削除する
void pop(int i) {
garbage_.push(i);
}
// 使用した最大のインデックス(+1)を得る
// この値より少し大きい値をreserveすることでメモリの再割り当てがなくなる
size_t size() {
return data_.size();
}
private:
vector<T> data_;
stack<int> garbage_;
};
// 連想配列
// Keyにハッシュ関数を適用しない
// open addressing with linear probing
// unordered_mapよりも速い
// nは格納する要素数よりも4~16倍ほど大きくする
template <class Key, class T>
struct HashMap {
public:
explicit HashMap(uint32_t n) {
n_ = n;
valid_.resize(n_, false);
data_.resize(n_);
}
// 戻り値
// - 存在するならtrue、存在しないならfalse
// - index
pair<bool,int> get_index(Key key) const {
Key i = key % n_;
while (valid_[i]) {
if (data_[i].first == key) {
return {true, i};
}
if (++i == n_) {
i = 0;
}
}
return {false, i};
}
// 指定したindexにkeyとvalueを格納する
void set(int i, Key key, T value) {
valid_[i] = true;
data_[i] = {key, value};
}
// 指定したindexのvalueを返す
T get(int i) const {
assert(valid_[i]);
return data_[i].second;
}
void clear() {
fill(valid_.begin(), valid_.end(), false);
}
private:
uint32_t n_;
vector<bool> valid_;
vector<pair<Key,T>> data_;
};
using Hash = uint32_t; // TODO
// 状態遷移を行うために必要な情報
// メモリ使用量をできるだけ小さくしてください
struct Action {
// TODO
Action() {
// TODO
}
};
using Cost = int; // TODO
// 状態のコストを評価するための構造体
// メモリ使用量をできるだけ小さくしてください
struct Evaluator {
// TODO
Evaluator() {
// TODO
}
// 低いほどよい
Cost evaluate() const {
// TODO
}
};
// 展開するノードの候補を表す構造体
struct Candidate {
Action action;
Evaluator evaluator;
Hash hash;
int parent;
Cost cost;
Candidate(Action action, Evaluator evaluator, Hash hash, int parent, Cost cost) :
action(action),
evaluator(evaluator),
hash(hash),
parent(parent),
cost(cost) {}
};
// ビームサーチの設定
struct Config {
int max_turn;
size_t beam_width;
size_t nodes_capacity;
uint32_t hash_map_capacity;
};
// 削除可能な優先度付きキュー
using MaxSegtree = atcoder::segtree<
pair<Cost,int>,
[](pair<Cost,int> a, pair<Cost,int> b){
if (a.first >= b.first) {
return a;
} else {
return b;
}
},
[]() { return make_pair(numeric_limits<Cost>::min(), -1); }
>;
// ノードの候補から実際に追加するものを選ぶクラス
// ビーム幅の個数だけ、評価がよいものを選ぶ
// ハッシュ値が一致したものについては、評価がよいほうのみを残す
class Selector {
public:
explicit Selector(const Config& config) :
hash_to_index_(config.hash_map_capacity)
{
beam_width = config.beam_width;
candidates_.reserve(beam_width);
full_ = false;
st_original_.resize(beam_width);
}
// 候補を追加する
// ターン数最小化型の問題で、candidateによって実行可能解が得られる場合にのみ finished = true とする
// ビーム幅分の候補をCandidateを追加したときにsegment treeを構築する
void push(Action action, const Evaluator& evaluator, Hash hash, int parent, bool finished) {
Cost cost = evaluator.evaluate();
if (finished) {
finished_candidates_.emplace_back(Candidate(action, evaluator, hash, parent, cost));
return;
}
if (full_ && cost >= st_.all_prod().first) {
// 保持しているどの候補よりもコストが小さくないとき
return;
}
auto [valid, i] = hash_to_index_.get_index(hash);
if (valid) {
int j = hash_to_index_.get(i);
if (hash == candidates_[j].hash) {
// ハッシュ値が等しいものが存在しているとき
if (cost < candidates_[j].cost) {
// 更新する場合
candidates_[j] = Candidate(action, evaluator, hash, parent, cost);
if (full_) {
st_.set(j, {cost, j});
}
}
return;
}
}
if (full_) {
// segment treeが構築されている場合
int j = st_.all_prod().second;
hash_to_index_.set(i, hash, j);
candidates_[j] = Candidate(action, evaluator, hash, parent, cost);
st_.set(j, {cost, j});
} else {
// segment treeが構築されていない場合
hash_to_index_.set(i, hash, candidates_.size());
candidates_.emplace_back(Candidate(action, evaluator, hash, parent, cost));
if (candidates_.size() == beam_width) {
// 保持している候補がビーム幅分になったとき
construct_segment_tree();
}
}
}
// 選んだ候補を返す
const vector<Candidate>& select() const {
return candidates_;
}
// 実行可能解が見つかったか
bool have_finished() const {
return !finished_candidates_.empty();
}
// 実行可能解に到達する「候補」を返す
vector<Candidate> get_finished_candidates() const {
return finished_candidates_;
}
void clear() {
candidates_.clear();
hash_to_index_.clear();
full_ = false;
}
private:
size_t beam_width;
vector<Candidate> candidates_;
HashMap<Hash,int> hash_to_index_;
bool full_;
vector<pair<Cost,int>> st_original_;
MaxSegtree st_;
vector<Candidate> finished_candidates_;
void construct_segment_tree() {
full_ = true;
for (size_t i = 0; i < beam_width; ++i) {
st_original_[i] = {candidates_[i].cost, i};
}
st_ = MaxSegtree(st_original_);
}
};
// 深さ優先探索に沿って更新する情報をまとめたクラス
class State {
public:
explicit State(/* const Input& input */) {
// TODO
}
// 次の状態候補を全てselectorに追加する
// 引数
// evaluator : 今の評価器
// hash : 今のハッシュ値
// parent : 今のノードID(次のノードにとって親となる)
void expand(const Evaluator& evaluator, Hash hash, int parent, Selector& selector) {
// TODO
}
// actionを実行して次の状態に遷移する
void move_forward(Action action) {
// TODO
}
// actionを実行する前の状態に遷移する
// 今の状態は、親からactionを実行して遷移した状態である
void move_backward(Action action) {
// TODO
}
private:
// TODO
};
// 探索木(二重連鎖木)のノード
struct Node {
Action action;
Evaluator evaluator;
Hash hash;
int parent, child, left, right;
// 根のコンストラクタ
Node(Action action, const Evaluator& evaluator, Hash hash) :
action(action),
evaluator(evaluator),
hash(hash),
parent(-1),
child(-1),
left(-1),
right(-1) {}
// 通常のコンストラクタ
Node(const Candidate& candidate, int right) :
action(candidate.action),
evaluator(candidate.evaluator),
hash(candidate.hash),
parent(candidate.parent),
child(-1),
left(-1),
right(right) {}
};
// 二重連鎖木に対する操作をまとめたクラス
class Tree {
public:
explicit Tree(const State& state, size_t nodes_capacity, const Node& root) :
state_(state)
{
nodes_.reserve(nodes_capacity);
root_ = nodes_.push(root);
}
// 状態を更新しながら深さ優先探索を行い、次のノードの候補を全てselectorに追加する
void dfs(Selector& selector) {
update_root();
int v = root_;
while (true) {
v = move_to_leaf(v);
state_.expand(nodes_[v].evaluator, nodes_[v].hash, v, selector);
v = move_to_ancestor(v);
if (v == root_) {
break;
}
v = move_to_right(v);
}
}
// 根からノードvまでのパスを取得する
vector<Action> get_path(int v) {
// cerr << nodes_.size() << endl;
vector<Action> path;
while (nodes_[v].parent != -1) {
path.push_back(nodes_[v].action);
v = nodes_[v].parent;
}
reverse(path.begin(), path.end());
return path;
}
// 新しいノードを追加する
int add_leaf(const Candidate& candidate) {
int parent = candidate.parent;
int sibling = nodes_[parent].child;
int v = nodes_.push(Node(candidate, sibling));
nodes_[parent].child = v;
if (sibling != -1) {
nodes_[sibling].left = v;
}
return v;
}
// ノードvに子がいなかった場合、vと不要な先祖を削除する
void remove_if_leaf(int v) {
if (nodes_[v].child == -1) {
remove_leaf(v);
}
}
// 最も評価がよいノードを返す
int get_best_leaf(const vector<int>& last_nodes) {
assert(!last_nodes.empty());
int ret = last_nodes[0];
for (int v : last_nodes) {
if (nodes_[v].evaluator.evaluate() < nodes_[ret].evaluator.evaluate()) {
ret = v;
}
}
return ret;
}
private:
State state_;
ObjectPool<Node> nodes_;
int root_;
// 根から一本道の部分は往復しないようにする
void update_root() {
int child = nodes_[root_].child;
while (child != -1 && nodes_[child].right == -1) {
root_ = child;
state_.move_forward(nodes_[child].action);
child = nodes_[child].child;
}
}
// ノードvの子孫で、最も左にある葉に移動する
int move_to_leaf(int v) {
int child = nodes_[v].child;
while (child != -1) {
v = child;
state_.move_forward(nodes_[child].action);
child = nodes_[child].child;
}
return v;
}
// ノードvの先祖で、右への分岐があるところまで移動する
int move_to_ancestor(int v) {
while (v != root_ && nodes_[v].right == -1) {
state_.move_backward(nodes_[v].action);
v = nodes_[v].parent;
}
return v;
}
// ノードvの右のノードに移動する
int move_to_right(int v) {
state_.move_backward(nodes_[v].action);
v = nodes_[v].right;
state_.move_forward(nodes_[v].action);
return v;
}
// 不要になった葉を再帰的に削除する
void remove_leaf(int v) {
while (true) {
int left = nodes_[v].left;
int right = nodes_[v].right;
if (left == -1) {
int parent = nodes_[v].parent;
if (parent == -1) {
cerr << "ERROR: root is removed" << endl;
exit(-1);
}
nodes_.pop(v);
nodes_[parent].child = right;
if (right != -1) {
nodes_[right].left = -1;
return;
}
v = parent;
} else {
nodes_.pop(v);
nodes_[left].right = right;
if (right != -1) {
nodes_[right].left = left;
}
return;
}
}
}
};
// ビームサーチを行う関数
vector<Action> beam_search(const Config& config, State state, Node root) {
Tree tree(state, config.nodes_capacity, root);
// 探索中のノード集合
vector<int> curr_nodes;
curr_nodes.reserve(config.beam_width);
// 本来は curr_nodes = {state.root_} とすべきだが, 省略しても問題ない
// 新しいノードの集合
vector<int> next_nodes;
next_nodes.reserve(config.beam_width);
// 新しいノード候補の集合
Selector selector(config);
for (int turn = 0; turn < config.max_turn; ++turn) {
// Euler Tour で selector に候補を追加する
tree.dfs(selector);
if (selector.have_finished()) {
// ターン数最小化型の問題で実行可能解が見つかったとき
Candidate candidate = selector.get_finished_candidates()[0];
vector<Action> ret = tree.get_path(candidate.parent);
ret.push_back(candidate.action);
return ret;
}
// 新しいノードを追加する
for (const Candidate& candidate : selector.select()) {
next_nodes.push_back(tree.add_leaf(candidate));
}
if (next_nodes.empty()) {
// 新しいノードがないとき
cerr << "ERROR: Failed to find any valid solution" << endl;
return {};
}
// 不要なノードを再帰的に削除する
for (int v : curr_nodes) {
tree.remove_if_leaf(v);
}
// ダブルバッファリングで配列を使い回す
swap(curr_nodes, next_nodes);
next_nodes.clear();
selector.clear();
}
// ターン数固定型の問題で全ターンが終了したとき
int best_leaf = tree.get_best_leaf(curr_nodes);
return tree.get_path(best_leaf);
}
} // namespace beam_search
それぞれの構造体やクラスについて見ていきます。
Object Pool
ビームサーチと直接の関係がないクラスです。
配列にオブジェクトを保存し、削除したオブジェクトの場所を再利用します。
また、std::vector などと同様に reserve でメモリを確保できるようにしました4。
最初は長さ4の空の配列とします。 3, 1, 4 を順に追加します。追加した場所である 0, 1, 2 を順に返します。 a[1] を削除します。 5 を追加します。a[1] と a[3] のどちらに追加してもよいのですが、最後に使用した場所を優先的に使用することにします。今回の例だと a[1] です。追加した場所である 1 を返します。 削除した場所のインデックスを保持することでこのような挙動を実装することができます。例を用いた説明
a[0]
a[1]
a[2]
a[3]
a[0]
a[1]
a[2]
a[3]
3
1
4
a[0]
a[1]
a[2]
a[3]
3
4
a[0]
a[1]
a[2]
a[3]
3
5
4
差分更新型のビームサーチでは、ノードの追加と削除を頻繁に繰り返します。Object Pool を使うことで次のようなメリットを享受できます。
- メモリの再利用により空間計算量を削減できる。
- メモリ上の連続した領域を使用するので、データがキャッシュに乗りやすくなる。
- 十分な大きさのメモリを最初に確保することで、メモリの再割り当てをなくすことができる。
HashMap
Selector でハッシュ値が重複した候補を除去するところで使います。
open addressing を使用し、インデックスが衝突したときは linear probing を行いました。(ハッシュ値に対する)ハッシュ関数がなく、挿入と一括削除しか行わないので、std::unordered_set よりも単純で高速に動作します。
Hash が整数型でないときは整数型に変換するか、HashMap を std::unordered_set に変更する必要があります。
ちなみに、元々私は std::unordered_set を使っていて、saharan さんのツイート を読んで参考にしたら速度が少し上がりました5。
Action
状態遷移に必要な情報をまとめます。ここでいう状態遷移は、親からの移動と親への移動の両方を指しています。
Evaluator
評価値を計算するための構造体です。
基本的な実装は次のようなものです。
struct Evaluator { Cost cost; Evaluator(Cost cost) : cost(cost) {} Cost evaluate() const { return cost; } };
Evaluator::evaluate でコストを返します。コストが低いほど採用されやすくなります。
補足: Action や Evaluator で何を保持すべきか
既に述べたように、状態遷移に必要な情報を Action で保持し、評価結果の比較に必要な情報を Evaluator で保持することを想定しています。
一方で、Action と Evaluator に、より多くの情報を持たせることもできます。
状態が変数 x をメンバとして保持し、状態を更新するときに毎度 x を更新するものとします。このとき、x を状態ではなく Action や Evaluator が保持するようにすれば、Euler Tour における x の更新を省略できます。状態の関数内で x を使用したいときには、Action や Evaluator のメンバにアクセスすればよいです。x の後退処理(Euler Tour における子から親への遷移)を実装する必要がなくなるというメリットもあります。
例えば、複数の評価項目があるときに、Evaluator で各評価項目の値を保持するということが考えられます。また、後退処理がなくなるため、浮動小数点数も扱いやすくなります6。
一方で、Action や Evaluator の使用メモリが小さいほどよいという側面もあるため、全ての変数を Action や Evaluator に保持すればいいわけではありません。更新が面倒で使用メモリが少ない変数だけを Action や Evaluator に保持するとよいと思います。
例えば、状態内で探索木の深さを管理する場合、深さを更新するときにインクリメントやデクリメントという非常に軽い処理しか行われないため、深さは状態に保持すればよいと思います。
ちなみに、Action と State を空にして Evaluator で全ての情報を保持するようにすると、愚直なビームサーチらしくなります。
Candidate
新しいノードの候補を表現します。
Selector
Candidate の中から新しいノードとして採用するものを選びます。採用された Candidate を元に新しいノードが追加されます。
新しいノードを生成してから不要なものを削除するという実装も考えられますが、木に対する操作は定数倍が重いため、Candidate 構造体を経由する実装になっています。
コードのコメントに書かれているように、ハッシュ値が一致した候補については評価が最もよいものに限定し、その中から評価がよい候補をビーム幅の個数だけ選びます。ハッシュ値の重複を検出するために自作の HashMap を使ったり、ソートをなくすために atcoder::segtree を削除可能な優先度付きキューとして使ったり、高速化を意識して実装しました。
ハッシュ値以外で多様性を確保したい場合、Selector を実装し直す必要があります。例えばスライドパズルなどで「現在のマスの座標が一致するものの中から上位 個を選ぶ」という場合には書き直す必要があります。
State
Euler Tour に沿って更新する情報をまとめたクラスです。問題ごとに各メソッドを実装する必要があります。
ビームサーチの最中に State がコピーされることはないため、空間計算量は大きくても構いません。一方で、各メソッドは速いほどよいです。
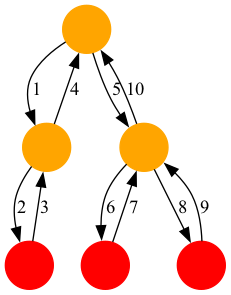
Tree
探索木を二重連鎖木で表現し、木に対する操作をまとめたクラスです。
- 親
- 1つ上の兄
- 1つ下の弟
- 最も上の子供
状態の更新順序は Euler Tour と一緒です。
一方で、二重連鎖木上では兄弟間を直接移動するようにします。
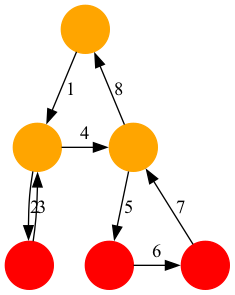
二重連鎖木のノードは配列を使用しないため、Euler Tour もノードの追加や削除も簡潔に実装できます。
不要なノードは全て削除します。不要なノードというのは、子ができなかった、あるいは子が全て削除されたノードのことです。
高速なビームサーチが欲しい!!! で紹介されているように、根から一本道の部分は反復しないようにします。
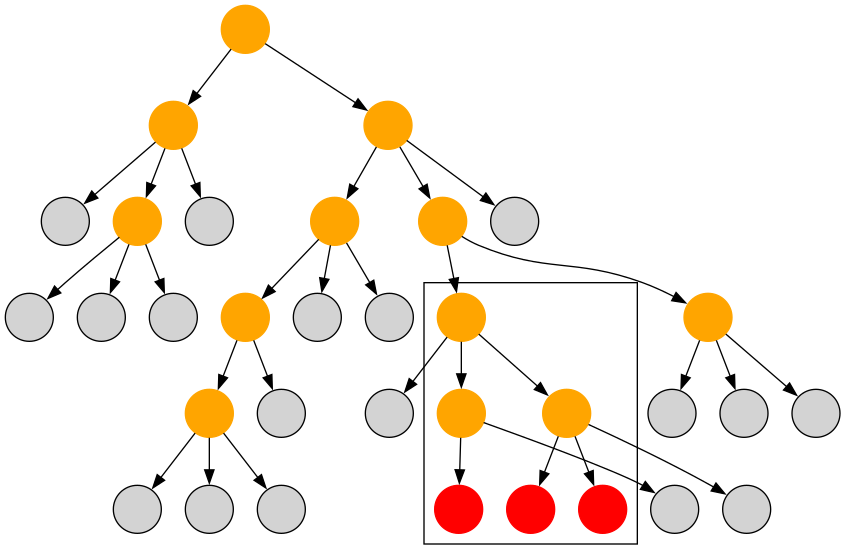
上図では探索したノードが全て描かれていますが、実際には灰色のノードは作成されず、さらに赤色のノードを子孫として持たない6つの橙色のノードは削除されていることに注意してください。
beam_search
ビームサーチを実行する関数です。ライブラリの外からこの関数を呼び出します。
使用例
TOYOTA Programming Contest 2023 Summer(AtCoder Heuristic Contest 021) の実装例を紹介します。
大まかな方針
番号が小さいボールから揃えます。
番号が最小のボール、あるいはその左上または右上のボールを、左上か右上に移動させます。

評価関数は次のように設定しました。小さいほうがよいです。
ハッシュ値は、揃えているボールの位置と、既に揃えたボールの位置の集合の2つから生成しました。
ライブラリの使い方を紹介することが目的なので、考察などは省略します。
ハッシュ関数 (2025/12/16 修正)
using Hash = uint32_t; constexpr Hash hash_mask = ((Hash(1) << 22) - Hash(1)) << 10; // 上位22ビット constexpr uint32_t xorshift32(uint32_t& x) { x ^= x << 13; x ^= x >> 17; x ^= x << 5; return x; } template <size_t N> constexpr array<uint32_t, N> make_position_hashes(uint32_t seed) { array<uint32_t, N> hashes{}; uint32_t x = seed; for (size_t i = 0; i < N; ++i) { hashes[i] = (xorshift32(x) & hash_mask); } return hashes; } constexpr array<uint32_t, n * n> position_hashes = make_position_hashes<n * n>(123456); // 下位10ビットをターゲット位置とする inline Hash update_target_position(Hash hash, int x, int y) { return (hash & hash_mask) | (x * n + y); } // 上位22ビットをソート済み位置のZobrist hashとする inline Hash update_sorted_position(Hash hash, int x, int y) { return hash ^ position_hashes[x * n + y]; }
下位10ビットで揃えているボールの位置を保持し、上位22ビットで既に揃えたボールの位置の集合の Zobrist hash を保持しました。
Action
struct Action { int xyxy; Action(int x1, int y1, int x2, int y2) { xyxy = x1 | (y1 << 8) | (x2 << 16) | (y2 << 24); } tuple<int,int,int,int> decode() const { return {xyxy & 255, (xyxy >> 8) & 255, (xyxy >> 16) & 255, xyxy >> 24}; } };
AHC021の場合、スワップ位置が分かれば盤面の更新が行えるため、スワップする2つの位置を保持しました。
4つの整数を1つの int にエンコードし、メモリ使用量を減らしています8。
Evaluator
using Cost = int; constexpr int target_coefficient = 600; struct Evaluator { int target_ball; int potential; Evaluator(int target_ball, int potential) : target_ball(target_ball), potential(potential) {} Cost evaluate() const { return potential - target_coefficient * target_ball; } };
2つの評価項目を保持しました。
State
更新部分だけ説明します。他の部分を読みたい場合は提出コードをご覧ください。
class State { public: void move_forward(Action action) { auto [x1, y1, x2, y2] = action.decode(); swap_balls(x1, y1, x2, y2); } void move_backward(Action action) { auto [x1, y1, x2, y2] = action.decode(); swap_balls(x1, y1, x2, y2); } private: vector<vector<int>> b_; array<pair<int,int>,m> positions_; void swap_balls(int x1, int y1, int x2, int y2) { int b1 = b_[x1][y1]; int b2 = b_[x2][y2]; b_[x1][y1] = b2; b_[x2][y2] = b1; positions_[b2] = {x1, y1}; positions_[b1] = {x2, y2}; } };
b_ は盤面を表しています。positions_[i] はボール i の位置を表します。 positions_[b_[x][y]] = {x, y} が成り立ちます。positions_ は、あるボールを揃えた後に次のボールの位置を得るときなどに使われます。
Evaluator が揃えたボールの数を保持するため、現在揃えているボールの番号を保持・更新する必要がないことに注意してください。
今回は2つのボールを入れ替えるだけなので move_forward と move_backward が等しくなっていますが、一般的には異なります。
提出コード
ビーム幅を3500に設定しました。
提出言語は C++ 20 (Clang 16.0.6) です。私のビームサーチライブラリ(の主に Selector)は GCC よりも Clang のほうが高速に動作するようでした。
他の使用例
ゲーム実況者Xの挑戦 の提出コードです。解説などは省略します。
ターンが飛ぶビームサーチの実装 (2025/03/16 追記)
1つの Action で2ターン以上後にも遷移できるビームサーチを実装しました。
ターンが等しいもの同士を比較して候補を選びます。
追加した候補とそれらの先祖を active に設定し、 active なノードだけ探索しています。
ターンを飛ばせない実装よりも一般化されていますが、速度に関して定数倍が重くなっているので、使い分けたほうがいいと思います。
(2025/07/29 追記)ノードの削除に関するバグを修正し、使用例を更新しました。各ノードに対して子が追加されうる最も遅いターンを管理し、ノードの削除が可能かどうかを判定するようにしました。
ビームサーチライブラリ
#include <bits/stdc++.h>
#include <atcoder/segtree>
using namespace std;
namespace beam_search {
// メモリの再利用を行いつつ集合を管理するクラス
template<class T>
class ObjectPool {
public:
// 配列と同じようにアクセスできる
T& operator[](int i) {
return data_[i];
}
// 配列の長さを変更せずにメモリを確保する
void reserve(size_t capacity) {
data_.reserve(capacity);
}
// 要素を追加し、追加されたインデックスを返す
int push(const T& x) {
if (garbage_.empty()) {
data_.push_back(x);
return data_.size() - 1;
} else {
int i = garbage_.top();
garbage_.pop();
data_[i] = x;
return i;
}
}
// 要素を(見かけ上)削除する
void pop(int i) {
garbage_.push(i);
}
// 使用した最大のインデックス(+1)を得る
// この値より少し大きい値をreserveすることでメモリの再割り当てがなくなる
size_t size() {
return data_.size();
}
private:
vector<T> data_;
stack<int> garbage_;
};
// 連想配列
// Keyにハッシュ関数を適用しない
// open addressing with linear probing
// unordered_mapよりも速い
// nは格納する要素数よりも4~16倍ほど大きくする
template <class Key, class T>
struct HashMap {
public:
explicit HashMap(uint32_t n) {
n_ = n;
valid_.resize(n_, false);
data_.resize(n_);
}
// 戻り値
// - 存在するならtrue、存在しないならfalse
// - index
pair<bool,int> get_index(Key key) const {
Key i = key % n_;
while (valid_[i]) {
if (data_[i].first == key) {
return {true, i};
}
if (++i == n_) {
i = 0;
}
}
return {false, i};
}
// 指定したindexにkeyとvalueを格納する
void set(int i, Key key, T value) {
valid_[i] = true;
data_[i] = {key, value};
}
// 指定したindexのvalueを返す
T get(int i) const {
assert(valid_[i]);
return data_[i].second;
}
void clear() {
fill(valid_.begin(), valid_.end(), false);
}
private:
uint32_t n_;
vector<bool> valid_;
vector<pair<Key,T>> data_;
};
using Hash = uint64_t; // TODO
// 状態遷移を行うために必要な情報
// メモリ使用量をできるだけ小さくしてください
struct Action {
// TODO
Action() {
// TODO
}
};
using Cost = int; // TODO
// 状態のコストを評価するための構造体
// メモリ使用量をできるだけ小さくしてください
struct Evaluator {
// TODO
Evaluator() {
// TODO
}
// 低いほどよい
Cost evaluate() const {
// TODO
}
};
// 展開するノードの候補を表す構造体
struct Candidate {
Action action;
Evaluator evaluator;
Hash hash;
int parent;
Cost cost;
Candidate(Action action, Evaluator evaluator, Hash hash, int parent, Cost cost) :
action(action),
evaluator(evaluator),
hash(hash),
parent(parent),
cost(cost) {}
};
// ビームサーチの設定
struct Config {
int max_turn;
size_t beam_width;
size_t nodes_capacity;
uint32_t hash_map_capacity;
};
// 削除可能な優先度付きキュー
using MaxSegtree = atcoder::segtree<
pair<Cost,int>,
[](pair<Cost,int> a, pair<Cost,int> b){
if (a.first >= b.first) {
return a;
} else {
return b;
}
},
[]() { return make_pair(numeric_limits<Cost>::min(), -1); }
>;
// ノードの候補から実際に追加するものを選ぶクラス
// ビーム幅の個数だけ、評価がよいものを選ぶ
// ハッシュ値が一致したものについては、評価がよいほうのみを残す
class Selector {
public:
explicit Selector(const Config& config) :
hash_to_index_(config.hash_map_capacity)
{
beam_width = config.beam_width;
candidates_.reserve(beam_width);
full_ = false;
st_original_.resize(beam_width);
}
// 候補を追加する
// ターン数最小化型の問題で、candidateによって実行可能解が得られる場合にのみ finished = true とする
// ビーム幅分の候補をCandidateを追加したときにsegment treeを構築する
bool push(Action action, const Evaluator& evaluator, Hash hash, int parent, bool finished) {
Cost cost = evaluator.evaluate();
if (finished) {
finished_candidates_.emplace_back(Candidate(action, evaluator, hash, parent, cost));
return true;
}
if (full_ && cost >= st_.all_prod().first) {
// 保持しているどの候補よりもコストが小さくないとき
return false;
}
auto [valid, i] = hash_to_index_.get_index(hash);
if (valid) {
int j = hash_to_index_.get(i);
if (hash == candidates_[j].hash) {
// ハッシュ値が等しいものが存在しているとき
if (cost < candidates_[j].cost) {
// 更新する場合
candidates_[j] = Candidate(action, evaluator, hash, parent, cost);
if (full_) {
st_.set(j, {cost, j});
}
return true;
}
return false;
}
}
if (full_) {
// segment treeが構築されている場合
int j = st_.all_prod().second;
hash_to_index_.set(i, hash, j);
candidates_[j] = Candidate(action, evaluator, hash, parent, cost);
st_.set(j, {cost, j});
} else {
// segment treeが構築されていない場合
hash_to_index_.set(i, hash, candidates_.size());
candidates_.emplace_back(Candidate(action, evaluator, hash, parent, cost));
if (candidates_.size() == beam_width) {
// 保持している候補がビーム幅分になったとき
construct_segment_tree();
}
}
return true;
}
// 選んだ候補を返す
const vector<Candidate>& select() const {
return candidates_;
}
// 実行可能解が見つかったか
bool have_finished() const {
return !finished_candidates_.empty();
}
// 実行可能解に到達する「候補」を返す
vector<Candidate> get_finished_candidates() const {
return finished_candidates_;
}
// 最も評価がよい候補を返す
Candidate calc_best_candidate() {
int best = 0;
for (size_t i = 0; i < candidates_.size(); ++i) {
if (candidates_[i].cost < candidates_[best].cost) {
best = i;
}
}
return candidates_[best];
}
void clear() {
candidates_.clear();
hash_to_index_.clear();
full_ = false;
}
private:
size_t beam_width;
vector<Candidate> candidates_;
HashMap<Hash,int> hash_to_index_;
bool full_;
vector<pair<Cost,int>> st_original_;
MaxSegtree st_;
vector<Candidate> finished_candidates_;
void construct_segment_tree() {
full_ = true;
for (size_t i = 0; i < beam_width; ++i) {
st_original_[i] = {candidates_[i].cost, i};
}
st_ = MaxSegtree(st_original_);
}
};
// ターン毎に候補を管理する
class MultiSelectors {
public:
explicit MultiSelectors(const Config& config) :
config_(config)
{
step_max_ = 1;
}
// 候補を追加する
// ターン数最小化型の問題で、candidateによって実行可能解が得られる場合にのみ finished = true とする
// stepは何ターン後に遷移するかを表す(普通のビームサーチなら1)
bool push(Action action, const Evaluator& evaluator, Hash hash, int parent, bool finished, size_t step) {
while (selectors_.size() < step) {
selectors_.emplace_back(Selector(config_));
}
if (selectors_[step - 1].push(action, evaluator, hash, parent, finished)) {
if (step > step_max_) {
step_max_ = step;
}
return true;
}
return false;
}
// expandの直前に呼ぶ
void reset_step_max() {
step_max_ = 1;
}
size_t get_step_max() const {
return step_max_;
}
// 次の候補を保持したSelectorを取り出す
Selector pop_selector() {
Selector ret = move(selectors_.front());
selectors_.pop_front();
return ret;
}
// Selectorを使い回す
void push_selector(Selector&& selector) {
selector.clear();
selectors_.push_back(move(selector));
}
private:
Config config_;
deque<Selector> selectors_;
size_t step_max_;
};
// 深さ優先探索に沿って更新する情報をまとめたクラス
class State {
public:
explicit State(/* const Input& input */) {
// TODO
}
// 次の状態候補を全てselectorに追加する
// 引数
// evaluator : 今の評価器
// hash : 今のハッシュ値
// parent : 今のノードID(次のノードにとって親となる)
void expand(const Evaluator& evaluator, Hash hash, int parent, MultiSelectors& multi_selectors) {
// TODO
}
// actionを実行して次の状態に遷移する
void move_forward(Action action) {
// TODO
}
// actionを実行する前の状態に遷移する
// 今の状態は、親からactionを実行して遷移した状態である
void move_backward(Action action) {
// TODO
}
private:
// TODO
};
// 探索木(二重連鎖木)のノード
struct Node {
Action action;
Evaluator evaluator;
Hash hash;
int parent, child, left, right;
bool active;
int remove_check_turn;
// 根のコンストラクタ
Node(Action action, const Evaluator& evaluator, Hash hash) :
action(action),
evaluator(evaluator),
hash(hash),
parent(-1),
child(-1),
left(-1),
right(-1),
active(true),
remove_check_turn(-1) {}
// 通常のコンストラクタ
Node(const Candidate& candidate, int right) :
action(candidate.action),
evaluator(candidate.evaluator),
hash(candidate.hash),
parent(candidate.parent),
child(-1),
left(-1),
right(right),
active(true),
remove_check_turn(-1) {}
};
// 二重連鎖木に対する操作をまとめたクラス
class Tree {
public:
explicit Tree(const State& state, size_t nodes_capacity, const Node& root) :
state_(state)
{
nodes_.reserve(nodes_capacity);
root_ = nodes_.push(root);
}
// 状態を更新しながら深さ優先探索を行い、次のノードの候補を全てselectorに追加する
void dfs(MultiSelectors& multi_selectors, int turn) {
remove_useless_nodes(turn);
update_root(turn);
int v = root_;
if (!nodes_[v].active) {
// activeなノードがないとき
return;
}
while (true) {
v = move_to_leaf(v);
multi_selectors.reset_step_max();
state_.expand(nodes_[v].evaluator, nodes_[v].hash, v, multi_selectors);
while (remove_nodes_.size() < multi_selectors.get_step_max()) {
remove_nodes_.emplace_back();
}
// 削除可能か確認するターンを設定する
remove_nodes_[multi_selectors.get_step_max() - 1].push_back(v);
nodes_[v].remove_check_turn = turn + multi_selectors.get_step_max();
v = move_to_ancestor(v);
if (v == root_) {
break;
}
}
}
// 根からノードvまでのパスを取得する
vector<Action> get_path(int v) {
// cerr << nodes_.size() << endl;
vector<Action> path;
while (nodes_[v].parent != -1) {
path.push_back(nodes_[v].action);
v = nodes_[v].parent;
}
reverse(path.begin(), path.end());
return path;
}
// 新しいノードを追加する
int add_leaf(const Candidate& candidate) {
int parent = candidate.parent;
int sibling = nodes_[parent].child;
int v = nodes_.push(Node(candidate, sibling));
nodes_[parent].child = v;
if (sibling != -1) {
nodes_[sibling].left = v;
}
// 祖先をactivateする
int u = parent;
while (!nodes_[u].active) {
nodes_[u].active = true;
if (u == root_) {
break;
}
u = nodes_[u].parent;
}
return v;
}
// 最も評価がよいノードを返す
int get_best_leaf(const vector<int>& last_nodes) {
assert(!last_nodes.empty());
int ret = last_nodes[0];
for (int v : last_nodes) {
if (nodes_[v].evaluator.evaluate() < nodes_[ret].evaluator.evaluate()) {
ret = v;
}
}
return ret;
}
private:
State state_;
ObjectPool<Node> nodes_;
int root_;
deque<vector<int>> remove_nodes_;
// 根から一本道の部分は往復しないようにする
void update_root(int turn) {
int child = nodes_[root_].child;
// 後で子供が追加されうるノードはスキップしないようにする
while (child != -1 && nodes_[child].right == -1 && nodes_[root_].remove_check_turn <= turn) {
root_ = child;
state_.move_forward(nodes_[child].action);
child = nodes_[child].child;
}
}
// ノードvの子孫で、最も左にある葉に移動する
int move_to_leaf(int v) {
int child = nodes_[v].child;
while (child != -1) {
// activeなノードが見つかるまで右に移動する
while (!nodes_[child].active) {
child = nodes_[child].right;
}
nodes_[v].active = false;
v = child;
state_.move_forward(nodes_[child].action);
child = nodes_[child].child;
}
nodes_[v].active = false;
return v;
}
// ノードvの先祖で、右への分岐があるところまで移動する
int move_to_ancestor(int v) {
while (v != root_) {
state_.move_backward(nodes_[v].action);
// activeなノードが見つかるまで右に移動する
int u = nodes_[v].right;
while (u != -1) {
if (nodes_[u].active) {
state_.move_forward(nodes_[u].action);
return u;
}
u = nodes_[u].right;
}
v = nodes_[v].parent;
}
return root_;
}
// 不要になったノードを全て削除する
void remove_useless_nodes(int turn) {
if (remove_nodes_.empty()) {
return;
}
for (int v : remove_nodes_.front()) {
if (nodes_[v].child == -1) {
remove_leaf(v, turn);
}
}
remove_nodes_.front().clear();
// 先頭の要素を末尾に移動
remove_nodes_.push_back(move(remove_nodes_.front()));
remove_nodes_.pop_front();
}
// 不要になった葉を再帰的に削除する
void remove_leaf(int v, int turn) {
while (true) {
if (nodes_[v].remove_check_turn > turn) {
// 子供が追加される可能性があるので削除しない
return;
}
int left = nodes_[v].left;
int right = nodes_[v].right;
if (left == -1) {
int parent = nodes_[v].parent;
if (parent == -1) {
cerr << "ERROR: root is removed" << endl;
exit(-1);
}
nodes_.pop(v);
nodes_[parent].child = right;
if (right != -1) {
nodes_[right].left = -1;
return;
}
v = parent;
} else {
nodes_.pop(v);
nodes_[left].right = right;
if (right != -1) {
nodes_[right].left = left;
}
return;
}
}
}
};
// ビームサーチを行う関数
vector<Action> beam_search(const Config& config, State state, Node root) {
Tree tree(state, config.nodes_capacity, root);
// 新しいノード候補の集合
MultiSelectors multi_selectors(config);
for (int turn = 0; turn < config.max_turn; ++turn) {
// Euler Tour で selector に候補を追加する
tree.dfs(multi_selectors, turn);
Selector selector = multi_selectors.pop_selector();
if (selector.have_finished()) {
// ターン数最小化型の問題で実行可能解が見つかったとき
Candidate candidate = selector.get_finished_candidates()[0];
vector<Action> ret = tree.get_path(candidate.parent);
ret.push_back(candidate.action);
return ret;
}
if (turn == config.max_turn - 1) {
// 最終ターン
Candidate candidate = selector.calc_best_candidate();
vector<Action> ret = tree.get_path(candidate.parent);
ret.push_back(candidate.action);
return ret;
}
// 新しいノードを追加する
for (const Candidate& candidate : selector.select()) {
tree.add_leaf(candidate);
}
// Selector を使い回す
multi_selectors.push_selector(move(selector));
}
unreachable();
}
} // namespace beam_search
スコアは改善していないですが、一応使用例を貼っておきます。
Euler Tour の辺を保持する実装 (2024/02/07 追記)
二重連鎖木や Object Pool を使うのではなく、探索木の有向辺を Euler Tour の順序で保持するほうが速いという話があり、実装してみました。
状態を差分計算するときは Euler Tour の配列に前から順にアクセスします。
探索木を更新するときは、辺の追加や削除をしながら、別の配列に Euler Tour をコピーしています。
ビームサーチライブラリ
#include <bits/stdc++.h>
using namespace std;
namespace beam_search {
// ビームサーチの設定
struct Config {
int max_turn;
size_t beam_width;
size_t tour_capacity;
uint32_t hash_map_capacity;
};
// 連想配列
// Keyにハッシュ関数を適用しない
// open addressing with linear probing
// unordered_mapよりも速い
// nは格納する要素数よりも16倍ほど大きくする
template <class Key, class T>
struct HashMap {
public:
explicit HashMap(uint32_t n) {
if (n % 2 == 0) {
++n;
}
n_ = n;
valid_.resize(n_, false);
data_.resize(n_);
}
// 戻り値
// - 存在するならtrue、存在しないならfalse
// - index
pair<bool,int> get_index(Key key) const {
Key i = key % n_;
while (valid_[i]) {
if (data_[i].first == key) {
return {true, i};
}
if (++i == n_) {
i = 0;
}
}
return {false, i};
}
// 指定したindexにkeyとvalueを格納する
void set(int i, Key key, T value) {
valid_[i] = true;
data_[i] = {key, value};
}
// 指定したindexのvalueを返す
T get(int i) const {
assert(valid_[i]);
return data_[i].second;
}
void clear() {
fill(valid_.begin(), valid_.end(), false);
}
private:
uint32_t n_;
vector<bool> valid_;
vector<pair<Key,T>> data_;
};
using Hash = uint32_t; // TODO
// 状態遷移を行うために必要な情報
// メモリ使用量をできるだけ小さくしてください
struct Action {
// TODO
Action() {
// TODO
}
bool operator==(const Action& other) const {
// TODO
}
};
using Cost = int;
// 状態のコストを評価するための構造体
// メモリ使用量をできるだけ小さくしてください
struct Evaluator {
// TODO
Evaluator() {
// TODO
}
// 低いほどよい
Cost evaluate() const {
// TODO
}
};
// 展開するノードの候補を表す構造体
struct Candidate {
Action action;
Evaluator evaluator;
Hash hash;
int parent;
Candidate(Action action, Evaluator evaluator, Hash hash, int parent) :
action(action),
evaluator(evaluator),
hash(hash),
parent(parent) {}
};
// ノードの候補から実際に追加するものを選ぶクラス
// ビーム幅の個数だけ、評価がよいものを選ぶ
// ハッシュ値が一致したものについては、評価がよいほうのみを残す
class Selector {
public:
explicit Selector(const Config& config) :
hash_to_index_(config.hash_map_capacity)
{
beam_width = config.beam_width;
candidates_.reserve(beam_width);
full_ = false;
costs_.resize(beam_width);
for (size_t i = 0; i < beam_width; ++i) {
costs_[i] = {0, i};
}
}
// 候補を追加する
// ターン数最小化型の問題で、candidateによって実行可能解が得られる場合にのみ finished = true とする
// ビーム幅分の候補をCandidateを追加したときにsegment treeを構築する
void push(const Candidate& candidate, bool finished) {
if (finished) {
finished_candidates_.emplace_back(candidate);
return;
}
Cost cost = candidate.evaluator.evaluate();
if (full_ && cost >= st_.all_prod().first) {
// 保持しているどの候補よりもコストが小さくないとき
return;
}
auto [valid, i] = hash_to_index_.get_index(candidate.hash);
if (valid) {
int j = hash_to_index_.get(i);
if (candidate.hash == candidates_[j].hash) {
// ハッシュ値が等しいものが存在しているとき
if (full_) {
// segment treeが構築されている場合
if (cost < st_.get(j).first) {
candidates_[j] = candidate;
st_.set(j, {cost, j});
}
} else {
// segment treeが構築されていない場合
if (cost < costs_[j].first) {
candidates_[j] = candidate;
costs_[j].first = cost;
}
}
return;
}
}
if (full_) {
// segment treeが構築されている場合
int j = st_.all_prod().second;
hash_to_index_.set(i, candidate.hash, j);
candidates_[j] = candidate;
st_.set(j, {cost, j});
} else {
// segment treeが構築されていない場合
int j = candidates_.size();
hash_to_index_.set(i, candidate.hash, j);
candidates_.emplace_back(candidate);
costs_[j].first = cost;
if (candidates_.size() == beam_width) {
// 保持している候補がビーム幅分になったときにsegment treeを構築する
full_ = true;
st_ = MaxSegtree(costs_);
}
}
}
// 選んだ候補を返す
const vector<Candidate>& select() const {
return candidates_;
}
// 実行可能解が見つかったか
bool have_finished() const {
return !finished_candidates_.empty();
}
// 実行可能解に到達するCandidateを返す
vector<Candidate> get_finished_candidates() const {
return finished_candidates_;
}
// 最もよいCandidateを返す
Candidate calculate_best_candidate() const {
if (full_) {
size_t best = 0;
for (size_t i = 0; i < beam_width; ++i) {
if (st_.get(i).first < st_.get(best).first) {
best = i;
}
}
return candidates_[best];
} else {
size_t best = 0;
for (size_t i = 0; i < candidates_.size(); ++i) {
if (costs_[i].first < costs_[best].first) {
best = i;
}
}
return candidates_[best];
}
}
void clear() {
candidates_.clear();
hash_to_index_.clear();
full_ = false;
}
private:
// 削除可能な優先度付きキュー
using MaxSegtree = atcoder::segtree<
pair<Cost,int>,
[](pair<Cost,int> a, pair<Cost,int> b){
if (a.first >= b.first) {
return a;
} else {
return b;
}
},
[]() { return make_pair(numeric_limits<Cost>::min(), -1); }
>;
size_t beam_width;
vector<Candidate> candidates_;
HashMap<Hash,int> hash_to_index_;
bool full_;
vector<pair<Cost,int>> costs_;
MaxSegtree st_;
vector<Candidate> finished_candidates_;
};
// 深さ優先探索に沿って更新する情報をまとめたクラス
class State {
public:
explicit State() {
// TODO
}
// EvaluatorとHashの初期値を返す
pair<Evaluator,Hash> make_initial_node() {
// TODO
}
// 次の状態候補を全てselectorに追加する
// 引数
// evaluator : 今の評価器
// hash : 今のハッシュ値
// parent : 今のノードID(次のノードにとって親となる)
void expand(const Evaluator& evaluator, Hash hash, int parent, Selector& selector) {
// TODO
}
// actionを実行して次の状態に遷移する
void move_forward(Action action) {
// TODO
}
// actionを実行する前の状態に遷移する
// 今の状態は、親からactionを実行して遷移した状態である
void move_backward(Action action) {
// TODO
}
private:
// TODO
};
// Euler Tourを管理するためのクラス
class Tree {
public:
explicit Tree(const State& state, const Config& config) :
state_(state)
{
curr_tour_.reserve(config.tour_capacity);
next_tour_.reserve(config.tour_capacity);
leaves_.reserve(config.beam_width);
buckets_.assign(config.beam_width, {});
}
// 状態を更新しながら深さ優先探索を行い、次のノードの候補を全てselectorに追加する
void dfs(Selector& selector) {
if (curr_tour_.empty()) {
// 最初のターン
auto [evaluator, hash] = state_.make_initial_node();
state_.expand(evaluator, hash, 0, selector);
return;
}
for (auto [leaf_index, action] : curr_tour_) {
if (leaf_index >= 0) {
// 葉
state_.move_forward(action);
auto& [evaluator, hash] = leaves_[leaf_index];
state_.expand(evaluator, hash, leaf_index, selector);
state_.move_backward(action);
} else if (leaf_index == -1) {
// 前進辺
state_.move_forward(action);
} else {
// 後退辺
state_.move_backward(action);
}
}
}
// 木を更新する
void update(const vector<Candidate>& candidates) {
leaves_.clear();
if (curr_tour_.empty()) {
// 最初のターン
for (const Candidate& candidate : candidates) {
curr_tour_.push_back({(int)leaves_.size(), candidate.action});
leaves_.push_back({candidate.evaluator, candidate.hash});
}
return;
}
for (const Candidate& candidate : candidates) {
buckets_[candidate.parent].push_back({candidate.action, candidate.evaluator, candidate.hash});
}
auto it = curr_tour_.begin();
// 一本道を反復しないようにする
while (it->first == -1 && it->second == curr_tour_.back().second) {
Action action = (it++)->second;
state_.move_forward(action);
direct_road_.push_back(action);
curr_tour_.pop_back();
}
// 葉の追加や不要な辺の削除をする
while (it != curr_tour_.end()) {
auto [leaf_index, action] = *(it++);
if (leaf_index >= 0) {
// 葉
if (buckets_[leaf_index].empty()) {
continue;
}
next_tour_.push_back({-1, action});
for (auto [new_action, evaluator, hash] : buckets_[leaf_index]) {
int new_leaf_index = leaves_.size();
next_tour_.push_back({new_leaf_index, new_action});
leaves_.push_back({evaluator, hash});
}
buckets_[leaf_index].clear();
next_tour_.push_back({-2, action});
} else if (leaf_index == -1) {
// 前進辺
next_tour_.push_back({-1, action});
} else {
// 後退辺
auto [old_leaf_index, old_action] = next_tour_.back();
if (old_leaf_index == -1) {
next_tour_.pop_back();
} else {
next_tour_.push_back({-2, action});
}
}
}
swap(curr_tour_, next_tour_);
next_tour_.clear();
}
// 根からのパスを取得する
vector<Action> calculate_path(int parent, int turn) const {
// cerr << curr_tour_.size() << endl;
vector<Action> ret = direct_road_;
ret.reserve(turn);
for (auto [leaf_index, action] : curr_tour_) {
if (leaf_index >= 0) {
if (leaf_index == parent) {
ret.push_back(action);
return ret;
}
} else if (leaf_index == -1) {
ret.push_back(action);
} else {
ret.pop_back();
}
}
unreachable();
}
private:
State state_;
vector<pair<int,Action>> curr_tour_;
vector<pair<int,Action>> next_tour_;
vector<pair<Evaluator,Hash>> leaves_;
vector<vector<tuple<Action,Evaluator,Hash>>> buckets_;
vector<Action> direct_road_;
};
// ビームサーチを行う関数
vector<Action> beam_search(const Config& config, const State& state) {
Tree tree(state, config);
// 新しいノード候補の集合
Selector selector(config);
for (int turn = 0; turn < config.max_turn; ++turn) {
// Euler Tourでselectorに候補を追加する
tree.dfs(selector);
if (selector.have_finished()) {
// ターン数最小化型の問題で実行可能解が見つかったとき
Candidate candidate = selector.get_finished_candidates()[0];
vector<Action> ret = tree.calculate_path(candidate.parent, turn + 1);
ret.push_back(candidate.action);
return ret;
}
assert(!selector.select().empty());
if (turn == config.max_turn - 1) {
// ターン数固定型の問題で全ターンが終了したとき
Candidate best_candidate = selector.calculate_best_candidate();
vector<Action> ret = tree.calculate_path(best_candidate.parent, turn + 1);
ret.push_back(best_candidate.action);
return ret;
}
// 木を更新する
tree.update(selector.select());
selector.clear();
}
unreachable();
}
} // namespace beam_search
元の二重連鎖木を使った実装よりも高速に動作するようでした。
最後に
この記事では私の実装のみを紹介しました。実装した人によって異なる部分があるので調べてみると面白いかもしれません。
最後まで読んでくださりありがとうございました。
- 若干意味合いが異なるかもしれません。私は同一視しています。↩
- 履歴は永続配列を使用することで高速化できます。↩
-
状態遷移の計算量が状態をコピーする計算量と同程度の場合には愚直なビームサーチでよいと思います。過去のAHCを見る限りだと、状態遷移が
の場合が多く、愚直なビームサーチが強い問題は少ないです。↩
-
内部的には
std::vector::reserveを呼び出しているだけです。↩ - open addressing と linear probing について参考にさせていただきました。私の実装では、遅延削除は行っていません。↩
-
浮動小数点演算を含む関数に対して、正確な逆関数を定義することは難しいことが多いです。例えば
として
から
を復元するときに、
を行うと思いますが、数値誤差を考慮すると
- 正確には ObjectPool におけるインデックスです。↩
- 16ビットにエンコードすることも可能ですが、個人的には限界まで減らすモチベーションがなかったです。↩